

Executive Summary
Massive MIMO (mMIMO) is central to achieving higher spectral efficiency and network capacity in 5G — and even more critical for 6G, where GPU Accelerated compute and power efficiency will define scalability. Benchmarking conducted here under the AI-WIN initiative, evaluates the performance and power efficiency of ODC’s GPU-accelerated Distributed Unit (DU) software, built on ODC’s MicroTask Architecture and NVIDIA’s Aerial GPU platform.
The results show that the GPU-accelerated DU eliminates the compute bottlenecks of CPU-only systems — delivering ≈ 380× faster Layer 2 mMIMO processing, ≈ 7× cell capacity, 3.5x better power efficiency per cell and 1.5x higher spectral efficiency.
In simple terms, this means operators can serve more users per site, consume less power, and scale toward AI-native 6G with a future-proof, software-defined architecture.
Together, ODC and NVIDIA demonstrate that AI-accelerated RANs are not just feasible — they are essential for delivering the scale, spectral efficiency, and energy performance expected in 6G
For more on the AI-WIN collaboration and how ODC and NVIDIA are redefining RAN intelligence visit: https://nvidianews.nvidia.com/news/nvidia-us-telecom-ai-ran-6g
From Bottlenecks to Breakthroughs
Three critical and time-consuming blocks dominate DL and UL mMIMO performance and compute complexity:
- SRS Channel Estimation
- MU-MIMO Orthogonality Checks & User Pairing
- Beamforming Weight Calculation
Maximizing the number of spatial layers/users that can be paired in every slot while meeting slot deadlines for these blocks is the key to achieving high per-cell UE density and Spectral Efficiency.
Benchmarking Configuration
| Parameter | Configuration |
|---|---|
| Duplex Mode | TDD |
| Subcarrier Spacing | 30 kHz |
| Channel Bandwidth | 100 MHz |
| TDD Pattern | DDDSUUDDDD (5 ms frame) |
| Cells Profiled | 6 (100 MHz each) |
| Antenna Configuration | 64T64R (mMIMO) |
| Layers | 16 DL & 8 UL |
| UE Configuration | 256UEs with SRS allocation |
| Number of SRS Symbols in 5 ms | 6 |
SRS Channel Estimation
SRS processing extracts per-antenna channel estimates from sounded ports. Profiling (100 MHz, 64T64R) shows per-cell CPU times increase with the number of SRS symbols. On GPU measured numbers are 6-cell aggregates; this document compares CPU (6-cell aggregate with 1vCPU assigned per cell) vs GPU (6-cell aggregate).
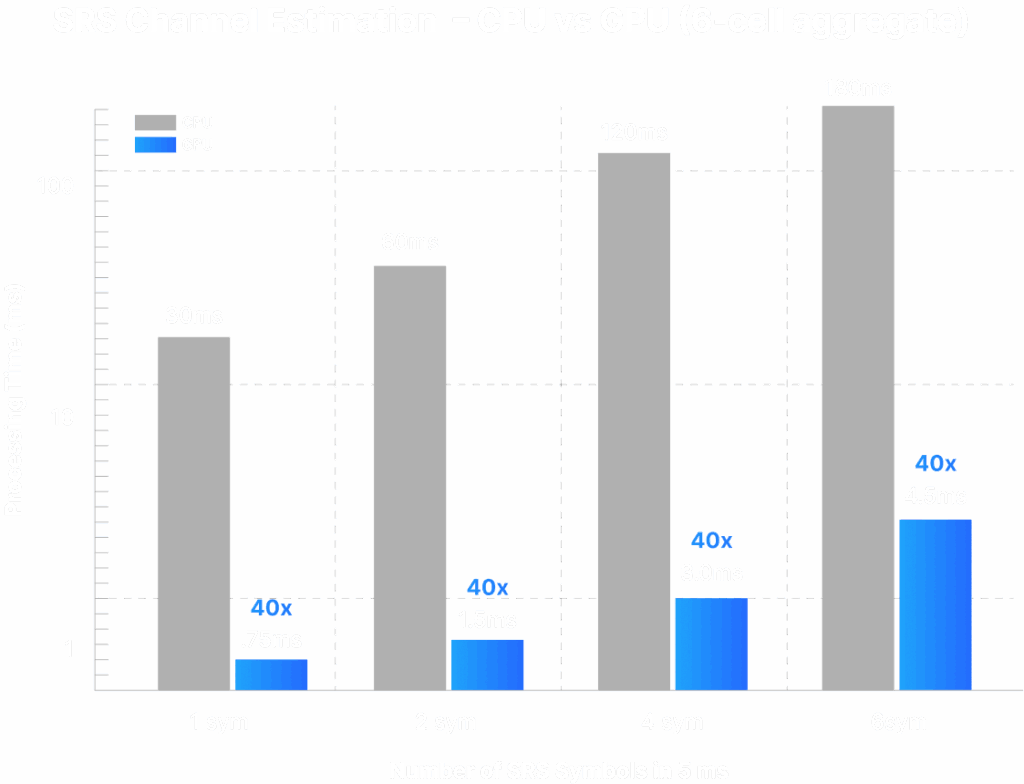
Key Takeaway #1:
GPU measured aggregates reduce SRS latency dramatically (e.g., measured 180 ms for CPU 6-cell 6 symbol vs 4.5 ms GPU 6-cell for the 6-symbol case — ~40× in aggregate; per-slot gains translate to fresher CSI for scheduling).
MU-MIMO Orthogonality Checks & User Pairing
Orthogonality checks are the functions that underpins user pairing. They scale with UE and SRS-port counts. GPUs accelerate both the orthogonality function and downstream pairing logic and scheduling, enabling real-time user pairing at scale.
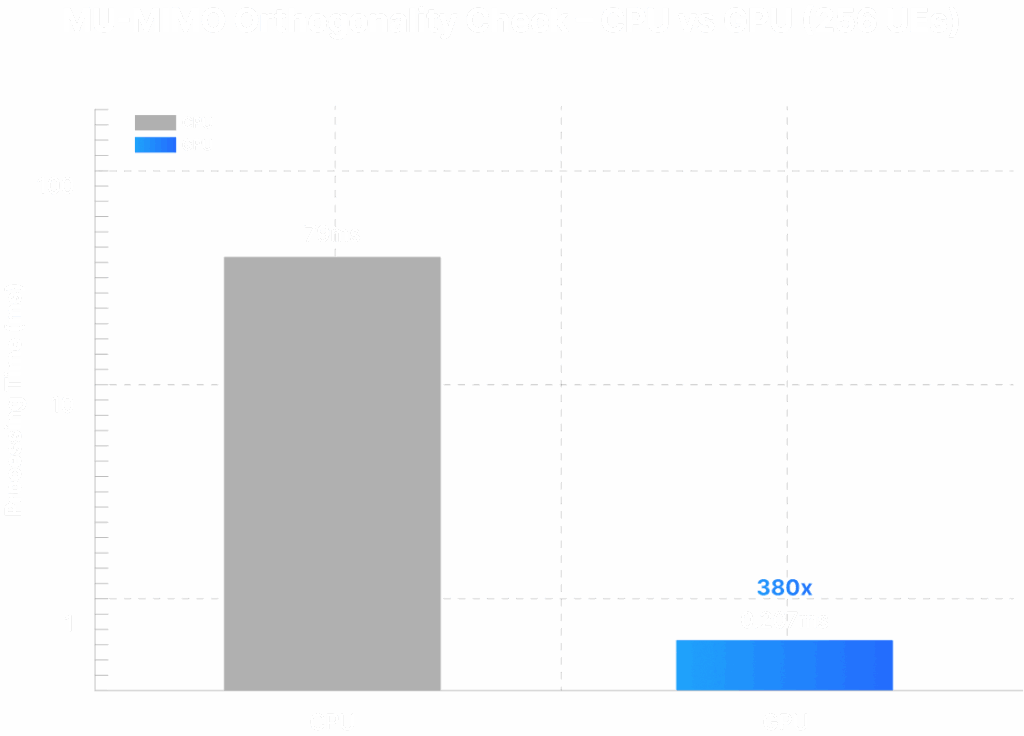
Key Takeaway #2:
At 256 UEs, GPU execution is 380× faster than CPU -> enabling dense MU-MIMO pairing and significant gains in spectral efficiency per cell.
Beamforming Weight Calculation
Beamforming (ZF/MMSE/SVD) is implemented as linear-algebra functions. Profiling shows measured times of ~400 µs on CPU (2 vCPUs assigned) vs ~60 µs on GPU for the studied case with ZF. These speedups free scheduling margin and make multi-cell coordination practical within slot timelines.
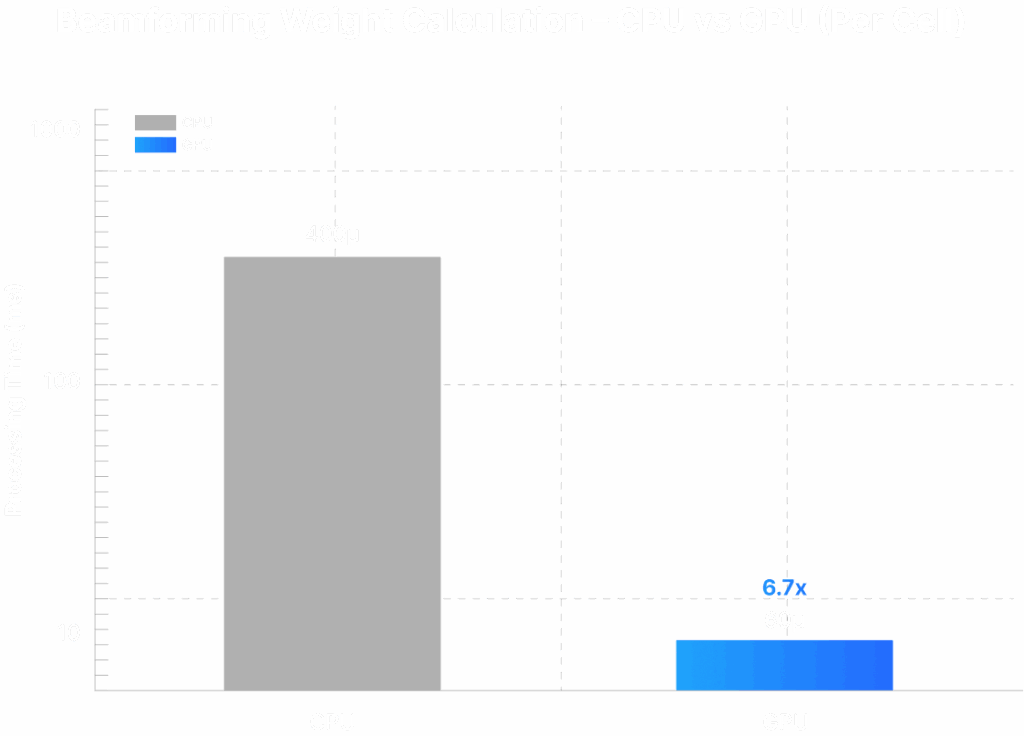
Key Takeaway #3:
Beamforming speedups on GPU (~6.7×) allow the DU to run more advanced precoding and multicell coordination without missing deadlines.
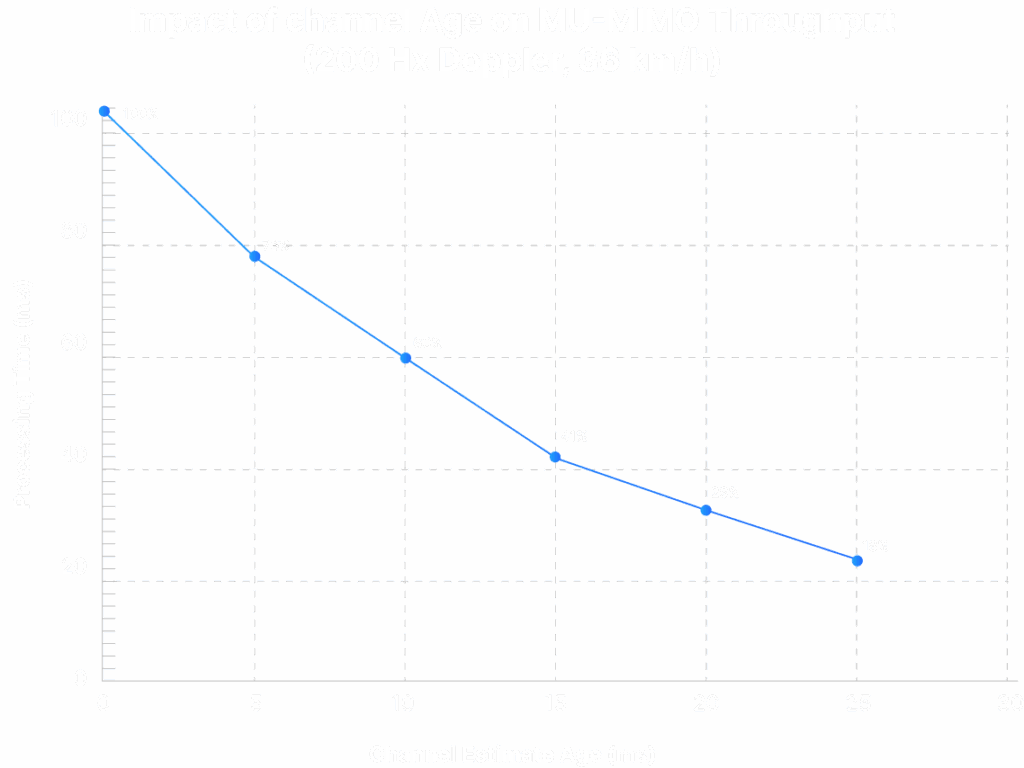
Throughput vs Channel Estimate Age (Why Real-Time Matters)
Channel estimates age quickly; stale estimates degrade MU-MIMO throughput. The chart below (200 Hz Doppler) shows throughput vs channel-age for basic ZF Beam forming technique. It demonstrates why SRS channel estimation and orthogonality must complete well within a 5 ms pattern to avoid throughput loss.
CPU Core Requirements and Operator Impact
Profiling (100 MHz, 64T64R, 256 UEs) shows CPU-only scaling becomes impractical. Even when SRS channel estimation and orthogonality checks are distributed over a 5 ms window, a CPU‑only system still requires approximately 144 vCPUs solely for these three mMIMO function blocks. In practice, the DU must also execute additional Layer 1, Layer 2, and transport functions — further increasing total compute demand. This highlights why GPU acceleration is essential for achieving scalable, power‑efficient, and future‑proof RAN deployments.
| Task | CPU-Only (typical) | GPU-Accelerated | Operator Impact (per cell) (Qualitative) |
|---|---|---|---|
| SRS Channel Estimation (6 symbols, 6 cells) | 180 ms | 4.5 ms | Timely CSI; Denser MU-MIMO |
| Orthogonality Checks & Pairing (For 256 UEs) | 79 ms | 0.29 ms | Dense MU-MIMO pairing; 1.5x higher spectral efficiency |
| Beamforming Weights | 400 µs | 60 µs | Enables slot-level coordination and advanced precoding |
| DU Compute Footprint | ~144 vCPUs (mMIMO only, 6-cell example) | Single GPU + reduced vCPUs | Higher per-cell UE density; simplified scaling |
Key Takeaway #4:
CPU only solution will not be able to scale beyond 32-64 SRS UEs/Cell -> Leads to a poor MUMIMO Spectral efficiency in dense urban cells
CPU Core Scaling Challenge
Profiling of 64T64R mMIMO deployments highlights the steep computational scaling of CPU-only Distributed Units (DUs). For instance, even a 6-cell DU configuration may require upwards of 144+ vCPUs. As the number of antennas and active UEs increase, CPU compute requirements grow non-linearly making it difficult to sustain slot deadlines within the 0.5 ms TDD boundary. This scaling challenge directly underscores the need for GPU acceleration to achieve real-time mMIMO performance and meet the densification goals of next-generation networks.
Power Efficiency and Hybrid DU Advantage
In a representative configuration, 4th Gen Intel® Xeon® Scalable processors with Intel® vRAN Boost with 32 core CPU system operating at 70% traffic load requires approximately one server per 2 cells to sustain a 100 MHz 64T64R mMIMO configuration — with advanced spectral and scheduling optimizations.
In contrast, a single Hybrid DU (CPU + GPU) system operating at the same 70% traffic load can efficiently support 14 or more cells, leveraging pooled compute resources and highly parallelized acceleration.
This translates to a ~3.5× improvement in per-cell power efficiency, significantly reducing energy draw, rack footprint, and operational overhead — enabling more sustainable and scalable RAN deployments.
Key Takeaway #5:
GPU-accelerated Hybrid DU delivers approximately 3.5× improvement in energy efficiency per served cell versus the CPU-only baseline
Enabling Intelligent RAN Acceleration with ODC MicroTask Architecture
ODC’s MicroTask Architecture is well suited to the NVIDIA accelerated computing platform, where a full stack approach enables fine-grained task partitioning across CPU and GPU resources, allowing RAN software to dynamically map compute-intensive PHY and MAC workloads onto NVIDIA GPUs while CPUs handle control and state. This hybrid CPU+GPU model ensures deterministic execution of channel estimation, orthogonality checks, beamforming, and scheduling within slot deadlines.
The same MicroTask framework extends beyond PHY acceleration into higher-layer intelligence—supporting ML-driven scheduling, user pairing, and cross-cell coordination. By leveraging NVIDIA’s GPU platforms (L4, H200 and next generation Blackwell), operators can incrementally introduce AI-driven optimization and 6G-ready features without re-architecting the RAN software. ODC’s silicon-agnostic design ensures flexibility, future-proofing deployments for next-generation RAN workloads.
Operator Takeaways
- Accelerate Core DU Functions: Offload L1 SRS estimation and MU-MIMO orthogonality computations and L2 Scheduler to NVIDIA GPUs to enable denser user multiplexing and higher spectral efficiency.
- Focus on Revenue-Linked KPIs: Prioritize spectral efficiency and per-cell UE density as primary KPIs directly impacting revenue-per-site.
- Maximize Energy Efficiency per Watt: Transitioning from CPU-only DUs to Hybrid DUs yields over 3.5x higher performance-per-watt, reducing power and rack footprint for massive MIMO deployments.
- Adopt a Hybrid CPU+GPU DU Architecture: Utilize the CPU for L2 control and state management while GPUs execute arithmetic-intensive PHY and L2 scheduling workloads. This hybrid model ensures deterministic slot-level performance, minimizes CPU contention, and achieves superior energy efficiency across larger cell deployments.
- Optimize Core Utilization: Offloading L2 scheduling workloads to GPUs reduces CPU contention, freeing processing headroom for control functions and enabling each DU to host additional cells — improving overall scalability and resource efficiency.
- Enable Incremental RAN Intelligence: GPU-accelerated DUs provide the compute headroom needed for ML-driven scheduling, channel prediction, and multi-cell coordination — paving the way for next-generation intelligent RANs.
Future Possibilities
Beyond current mMIMO acceleration, the ODC–NVIDIA collaboration sets the foundation for next-generation RAN intelligence. The same CPU+GPU hybrid infrastructure can seamlessly extend to ML-driven SRS channel prediction, AI-based scheduling, and advanced Giga-MIMO coordination across multiple cells. These innovations not only improve spectral efficiency but also enable the RAN to evolve into an adaptive, software-defined platform—ready for 6G and autonomous network operations.
Conclusion
ODC’s MicroTask Architecture, together with NVIDIA GPUs, makes dense, real-time massive MIMO practical. By routing parallel numeric kernels to GPUs and keeping control/state on CPUs, operators can meet slot deadlines, increase per-cell UE density, and incrementally add ML-driven scheduling and multi-cell coordination while keeping the RAN software future-proof for next-generation silicon and 6G.